Paper and Codes Edited on Typora Zhuoyi Huang, 2020.7.14
总结
-
本文提出了一种新的全身人类神经渲染模型。
- 特点:
- new viewpoints(top), new body poses(bottom) 不同的身体姿势和不同的摄像机位
- 通过视频进行训练
- 可从表面几何或运动建模中分离纹理
- 采用的方法:explicit texture representation + rendering neural network
- 显式模型表面2D纹理估计+渲染神经网络(经典的计算机图形(Computer Graphics)方法与深度神经网络进行结合)
- 与其他方法的比较效果:
- 与直接从图像到图像的转化(Image-to-Image translation)方法相比,保留个性化的纹理映射可以实现更好的泛化。
- 避免了在3D中进行显式的形状建模。

- 特点:
相关工作
- 与标准的计算机图形学流水线对比:
- 估计用户个性化的中性位置的人体网格,执行skinning(中性姿势的变形),以及将生成的3D表面投影到图像坐标上,同时叠加特定于人的2D纹理。
- 本文:简化经典流水线的多个阶段,并用单个网络代替它们,该网络学习从
- 输入(人体关节的位置)——>输出(2D图像)的映射。
- 结合了经典计算机图形学中的思想,即使用深度卷积神经网络将几何形状和纹理分离。
- 保留2D纹理可增强在相机转换和人体关节之间有效转移人体碎片的外观的泛化能力。
- 卷积网络的作用:
- 在给定身体姿势和相机参数的情况下预测输出2D图像中各个像素的纹理坐标
- 预测人体foreground/background mask.
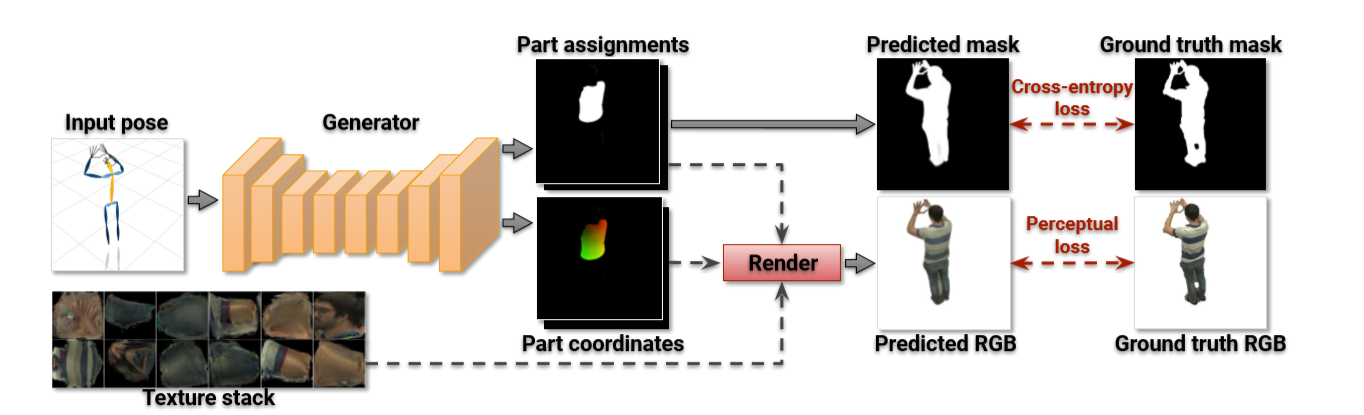
论文模型
数学抽象
\[B_{i} 表示一个三阶张量/三维array,对应于第i个训练或测试图像\] \[B_{i}^{j}[x, y] 表示位于位置(x,y)的map堆栈Bi的第j个map中的标量元素\] \[B_{i}[x, y]表示与在位置(x,y)采样的所有map相对应的元素向量\]输入输出:
一般来说,我们感兴趣的是根据一个人的姿势合成图像。姿势的形式: 在摄像机坐标系中定义的三维关节位置。
-
输入:
\[并使用这些插值来定义地图B_{i}^{j}中与骨骼像素(未被第j个bone覆盖的像素被设置为零)相对应的值。\]\(图栈B_{i}, 包含了关于人和相机姿势的信息。\) \(每个B_{i}^{j}包含了投影在摄像机平面上的“火柴人”(骨架)的,第j个栅格化的片段(骨骼)。\) \(为了保留有关关节第三坐标的信息,在关节之间线性地定义各段的深度值,\)
- 输出:
\[一个RGB图像(一个三通道堆栈)I_{i}和一个定义Avatar所覆盖的像素的单通道mask M_{i}\]
-
两种方法:
- \[baseline:直接翻译,将B_{i}映射到{I_{i},M_{i}}\]
- \[Textured neural Avatar:间接执行上述映射\]
一些细节
- 遵循DensePose的方法。
- 依赖于ConvNets的泛化能力,并且将很少的领域特定知识纳入系统中。
- 我们使用带纹理的化身方法,该方法可显式估计身体部位的纹理,从而确保在变化的姿势和相机下,身体表面外观具有相似性。
- 将身体细分为n = 24个部分,其中每个部分都有2D参数化。每个身体部位还具有纹理 , \(map T^{k}\)
-
该贴图为固定大小的彩色图像(在我们的实现中为256×256)。
-
纹理神经化身的训练过程估计个性化的body part参数和纹理。
-
与DensePose不同,DensePose的部位分配和身体部位坐标是从图像中得出的,我们在测试时的方法旨在仅基于姿态预测它们。
-
流程:
-
\(Given: 姿势由B_{i}定义\) \(翻译网络: 预测身体部位分配的堆栈(Part assignments)P_{i},和身体部位坐标堆栈(Part coordinates)C_{i}\)
-
Part assignments \(P_{i}包含n + 1个非负数的map,这些map加总为1(即P_{n}对于任何位置(x,y),\sum_{k=0}^{n} P_{i}^{k}[x, y]=1)\) \(将对于k = 0,...,n-1的映射通道P^k_i解释为像素属于第k个身体部位的概率,并且映射通道P^n_i对应于背景的概率。\)
-
Part coordinates \(C_{i}包含2n个介于0和w之间的实数map,其中w是纹理图T^{k}的空间大小(宽度和高度)\) \(坐标图C_{2k}^i和C_{2k + 1}^i对应于第k个身体部位上的像素坐标。\) \(坐标 map C_{2k}^i和C_{2k + 1}^i对应于第k个身体部位上的像素坐标。\)
-
通过Part assignment 和 Part coordinates得到image \(具体来说,一旦预测了Part assignment(P_i)和part coordiantes(C_i)\)
\[将每个像素(x,y)处的图像I_i重建为纹理的加权组合,其中权重和纹理坐标由P_i和相应的C_i规定:\] \[\begin{aligned} s\left(P_{i}, C_{i}, T\right)[x, y] &=\sum_{k=0}^{n-1} P_{i}^{k}[x, y] \\ & T^{k}\left[C_{i}^{2 k}[x, y], C_{i}^{2 k+1}[x, y]\right] \end{aligned}\] \[其中s(·,·,·)是给定三个输入参数输出RGB映射堆栈的采样函数(layer)。\] \[纹理映射T^k是使用双线性插值在非整数位置\left(C_{i}^{2 k}[x, y], C_{i}^{2 \dot{k}+1}[x, y]\right)以分段可微的方式采样\]
-
损失函数:
- 为了学习纹理神经化身的参数,优化了生成图像和ground truth图像之间的损失:
-
优化用于测量ground truth背景与背景mask预测之间的差异的mask loss \(\mathcal{L}_{\operatorname{mask}}(\phi, T)=d_{\mathrm{BCE}}\left(\overline{1}-M_{i}, g_{\phi}^{P}\left(B_{i}\right)^{n}\right)\)
\[d_{BCE} 是二进制交叉熵损失g^P_{\phi}(B_i)^n对应于预测出的Part assignment堆栈的第n个(即背景)通道。\]
-
网络的成功取决于初始化策略。
- 从多个视频序列进行训练时,我们使用DensePose系统[28]初始化TNA。
实验
对比Direct, Video-to-Video,和本文提出的方法。
- 网站进行用户研究
- SSIM score和Frechet distance
- 多视频比较+单视频比较
- 结果:

- 用户研究结果有优势。
- 定量指标上具有缺点,因为会从不同的角度对照明进行平均。
- 分析:
- Pros: 与直接映射方法相比,保留明确的形状和纹理分离有助于实现更好的泛化。
- Cons:
- 泛化能力仍然受到限制,因为当以与训练集显着不同的比例渲染某个人时,泛化能力无法很好地泛化。
- 此外,在手和脸上存在姿势估计错误的情况下,纹理化身会表现出强烈的伪影。
- 最后,本方法假定表面颜色恒定,并忽略照明效果。
- Solutions:
- 可以通过在渲染之前重新缩放比例,然后进行裁剪/填充后处理来部分解决泛化能力问题。
- 通过使本方法的纹理依赖于视图和光照来解决第三个问题。